(note – read the general intro first – this is probably more detailed / domain specific than what you want to start with)
(note 2 – I (Mike) have added the headings and formatting. For comments I’ve added, i’ve italicized things)
The paper referenced in the text below is available from IJLM0102_Shaffer.
The Context: What is the domain?
Epistemic games are based on a specific theory of learning: the epistemic frame hypothesis. The epistemic frame hypothesis suggests that any community of practice has a culture and that culture has a grammar, a structure composed of:
- Skills: the things that people within the community do
- Knowledge: the understandings that people in the community share
- Identity: the way that members of the community see themselves
- Values: the beliefs that members of the community hold
- Epistemology: the warrants that justify actions or claims as legitimate within the community
This collection of skills, knowledge, identity, values, and epistemology forms the epistemic frame of the community. The epistemic frame hypothesis claims that: (a) an epistemic frame binds together the skills, knowledge, values, identity, and epistemology that one takes on as a member of a community of practice; (b) such a frame is internalized through the training and induction processes by which an individual becomes a member of a community; and (c) once internalized, the epistemic frame of a community is used when an individual approaches a situation from the point of view (or in the role) of a member of a community.
Put in more concrete terms, engineers act like engineers, identify themselves as engineers, are interested in engineering, and know about physics, biomechanics, chemistry, and other technical fields. These skills, affiliations, habits, and understandings are made possible by looking at the world in a particular way: by thinking like an engineer. The same is true for biologists but for different ways of thinking—and for mathematicians, computer scientists, science journalists, and so on, each with a different epistemic frame.
Epistemic games are thus based on a theory of learning that looks not at isolated skills and knowledge, but at the way skills and knowledge are systematically linked to one another—and to the values, identity, and ways of making decisions and justifying actions of some community of practice.
The domain problem: assessment of Epistemic Games / Epistemic Frames
To assess epistemic games, then, we begin with the concept of an epistemic frame. The kinds of professional understanding that such games develop is not merely a collection of skills and knowledge—or even of skills, knowledge, identities, values, and epistemologies. The power of an epistemic frame is in the connections among its constituent parts. It is a network of relationships: conceptual, practical, moral, personal, and epistemological.
Epistemic games are designed based on ethnographic analysis of professional learning environments, the capstone courses and practica in which professionals-in-training take on versions of the kinds of tasks they’ll do as professionals. Interspersed in these activities are important opportunities for feedback from more experienced mentors. In earlier work, I explored a few ways of providing technical scaffolds to help young people meaningfully engage in the professional work of science journalists. I also conducted an ethnography of journalism training practices, studying a reporting practicum course on campus. This has led to my current effort: seeking to better understand how we might measure and articulate the similarities and differences between the writing feedback in different venues – in this case, copyediting feedback given in the journalism practicum, copyediting feedback given in a journalism epistemic game, and copyediting feedback given in a graduate level psychology course (i.e., a non-journalism contrast venue).
I’m particularly interested in differentiating the kinds of writing feedback that are more characteristic of journalism from more general writing feedback. In order to investigate these patterns quantitatively, the feedback from each venue has been segmented (each comment from each writing assignment for each participant in each venue was treated as a separate data segment) and coded for the presence/absence of a number of categories (for a graphic example of this using a different data set, see the attached paper, p.6). Using epistemic network analysis, the resulting data set can then be used to investigate such ideas as the relative centrality of particular frame elements, i.e., the extent to which particular aspects of journalistic expertise (categories of skills / knowledge / values / identity / epistemology) are linked together in the feedback provided.
The challenge: Comparing Epsitemic Frame Networks
The design challenge arises when we try to compare this multidimensional data set across venues. It is unwieldy to say the least to try to compare multiple sets of 17 items. We can overcome that by first calculating the root mean square of the 17 relative centrality values, then scale the resulting values to achieve a single similarity index for the set, and finally compare those values. However, this involves collapsing a number of dimensions that a) might not properly be collapsed, and b) might be useful for providing an overall profile for comparison.
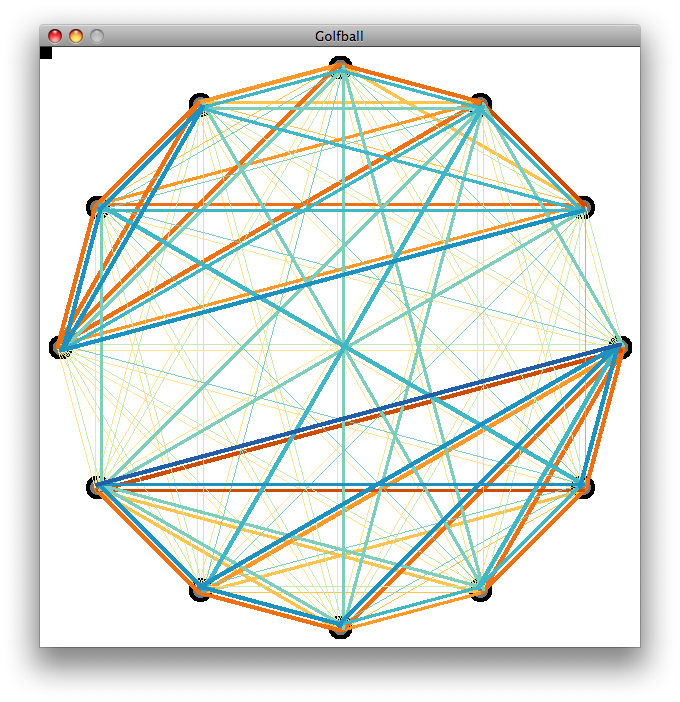
As a way of retaining potentially important dimensional information, we’re also trying a multidimensional scaling technique, principle coordinates analysis (similar to principle component analysis), to identify a subset of coordinates we might then use to map the different venue’s data and produce 2 or 3-dimensional, i.e., graph-able representations of the data for comparison. The challenge of how to represent these multi-dimensional data sets remains.
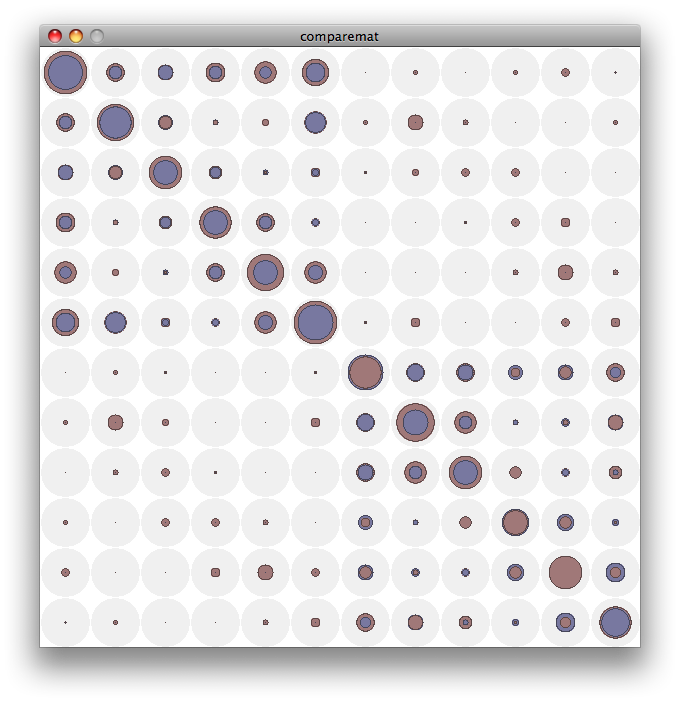
There is another challenge inherent in our relative centrality metric: it calculates the centrality of a given element by summing the co-occurrences of a particular element with any other element, meaning it collapses the specific linkages taking place to provide a more general indication of the importance of the element. Comparing data from different venues though reveals that two elements from different venues with the same relative centrality values can actually be linked to quite different specific elements. In the terms of this data set, this would be something like data from both the practicum venue and the psychology venue showing Knowledge of Story as highly central, while a closer inspection of the links occurring reveals they are linked quite differently in each case.
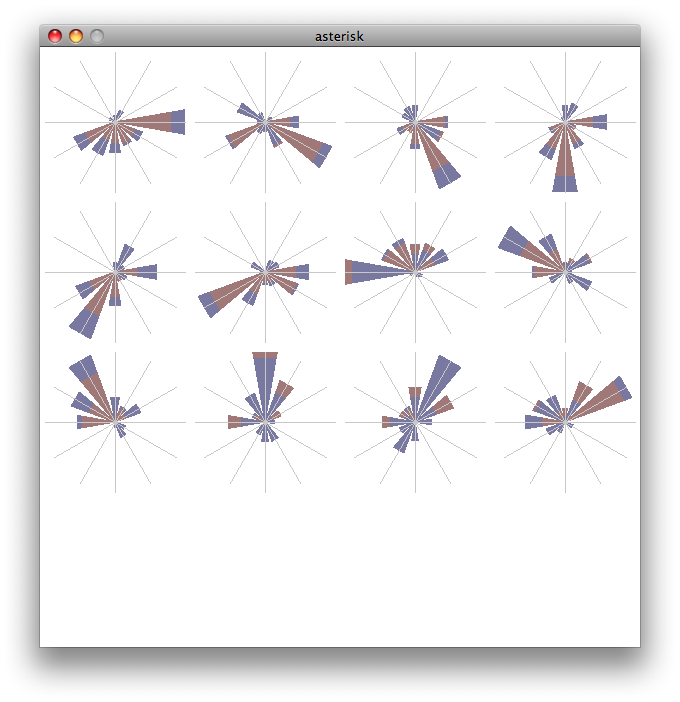
So, I’ve produced a new metric, relative link strength (RLS), which, like the relative centrality metric, is based on the co-occurrence of epistemic frame elements in the data segments. However, instead of collapsing these co-occurrence frequencies into a single value, RLS retains the specificity, producing a matrix of link frequencies between every pair of the codes (frame elements). This is particularly useful for drilling into the apparently similar relative centrality values between different contexts, but takes an unwieldy representational set of 17 elements and makes it even more complex as a matrix of 17 by 17 elements. Even focusing on a particularly interesting subset of 8 elements means figuring out the best way to show an 8×8 matrix. Working solutions to this so far include generating radar plots for each of the elements (the rows of the matrix, if you will) with each venue represented in semi-transparent solid fills to get a sense of the similarity / difference between the venues on each dimension. This approach is better than some, but has drawbacks.
Looking forward to thinking through this and the overall similarity representation with the group.