
VARD & ASCII Symbols
Yes, even ASCII symbols mess up VARD.
Those who have tried to extract plain text from TCP TEI P4 or P5 XML files know how difficult it is. While coding tools to extract TCP text, the VEP team grappled with the order of operations to perform. Where is the best place in an extraction pipeline to convert the XML document to text? Where do we want to use VARD?
As discussed in my previous post, processing XML files through VARD can be tricky. Non-ASCII symbols and XML tags interrupt the words that VARD needs to check against its dictionary, preventing VARD from recognizing words in their entirety.
For the most part, VARD cannot process even ASCII symbols as part of words, which has implications for extracting and representing TCP XML files. In order to process TCP XML, the VEP team has had construct its character cleaner and text extractor to work with VARD’s constraints regarding symbols and XML tags. Furthermore, character cleaning and text extraction had to align with editorial principles. To illustrate, the team had to consider the extent to which its algorithms modified TCP text. TCP XML file structure and contents further complicated the modification. When extracting text, did we only want to extract what was definite (the characters) or also preserve the traces of illegibility (characters represented by symbols)?
In the end, VEP decided to design character cleaning and text extraction tools that preserve textual information. It required figuring out character substitutions that worked with VARD to account for symbols nested within words. If a word contained illegible characters, the number of illegible characters would be maintained. However, the TCP’s bullet point that represents illegible characters doesn’t allow VARD to read the surrounding characters as one word.
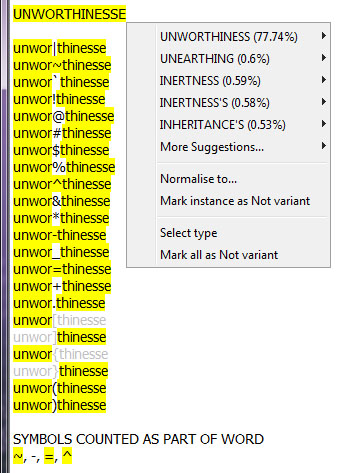
To address the dilemma, I generated a test text file with a word that had symbols interrupting it, quite like you will find in TCP corpora. I recreated the test for the post today, using the word unworthinesse. I wanted to see which ASCII symbols VARD would treat as part of words. As you can see in the screen capture to the left of VARD’s GUI, VARD successfully treats several ASCII characters as part of words–the entire word is highlighted. For the symbols not treated as part of the word,VARD doesn’t highlight them. Unsurprisingly VARD treats hyphens (-) as part of a word. Hyphens are a common feature of compound adjectives. Other ASCII symbols VARD recognizes are the tilde (~), the caret (^), and the equals sign (=).
When designing the character cleaner for TCP corpora, the VEP team leveraged the knowledge of how VARD handles ASCII symbols in the following way:
- Illegible characters(bullet: •) replaced by the caret (^). TCP: we•e | VEP: we^re
- Unrecognized punctuation (small black square: ▪) replaced by the asterisk (*). TCP: long ago▪ | VEP: long ago*
- Unrecognized characters and common textual symbols (e.g., the pilcrow (¶)) replaced by at sign (@). TCP: ¶Behold, | VEP unstripped text: @Behold, | VEP stripped text: Behold,
- Missing words (lozenge in angle brackets: 〈◊〉) replaced by ellipses in parentheses ((…)).
With the above scheme we preserve as much textual information as possible. With caret replacements, VARD has the opportunity to standardize words that have illegible characters.
Future versions of our character cleaner may take advantage of the tilde () to help represent letters with macrons (ā to a).
Our character cleaner also removes certain XML tags to give the flexibility of using VARD on TCP files in text or XML format.
tags of decorative initials — T he- Superscript — 13th
Subscript — X2
- XML comments — <!– handkeyed by person –!>
Of course, a final caution for VARDing XML files: make sure the program processes only the text that you want it to. VARD automatically ignores XML tags. It’s still going to alter what is between those tags, especially in the HEADER of the XML file, which contains the metadata. To make sure VARD doesn’t change the metadata, add the following entries to VARD’s “text_to_ignore.txt” file in the setup folder (it contains the code for ignoring XML tags):
- (?s)
.* - (?s)
.* - (?s)
.* - (?s)
.* - (?s)
.*
Why are there so many? Because coding practices are incredibly variable.