
Making your own rules for use with Ubiqu+Ity
Several years ago, Michael Witmore and Jonathan Hope published a paper in Shakespeare Quarterly that describes how the string-matching rhetorical analysis software DocuScope is able to identify stylistic fingerprints of genre in Shakespeare’s plays. Visualizing English Print is proud to make the string-matching rules used by DocuScope available online for general use as part of the multivariate textual analysis package Ubiqu+Ity.
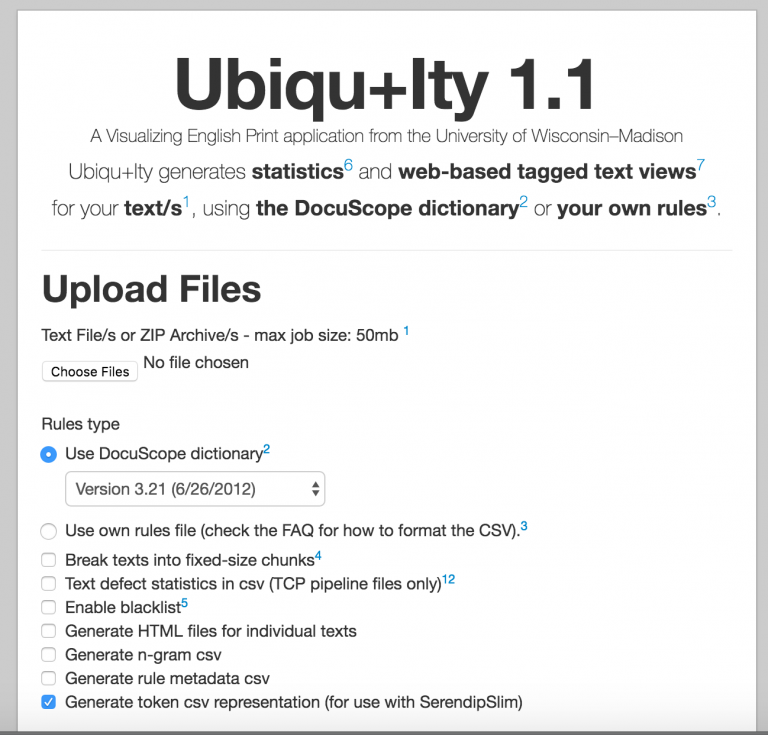
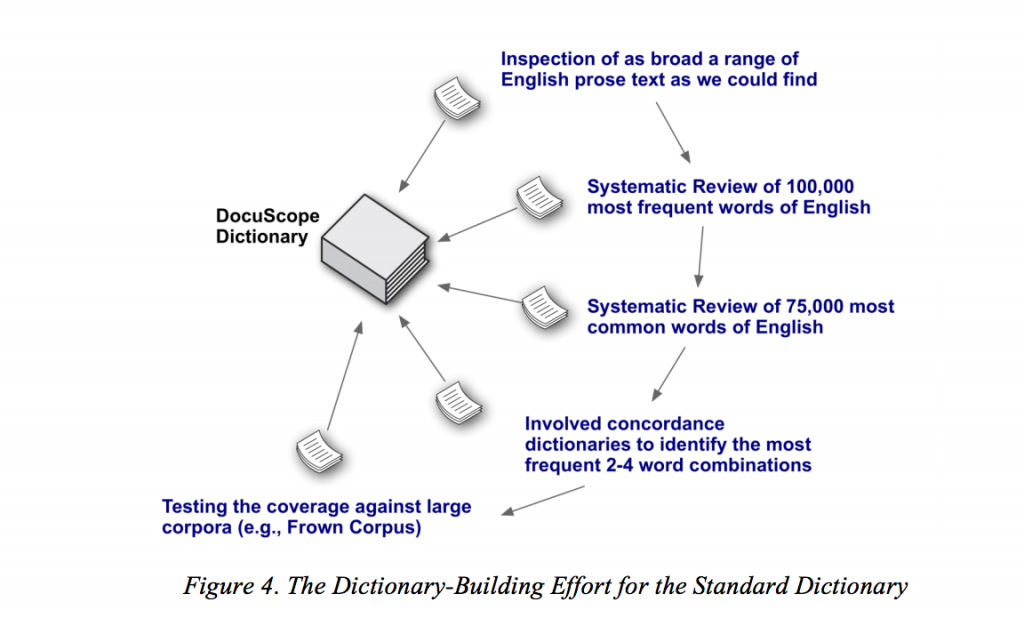
The DocuScope dictionaries, which were initially designed to analyze rhetorical features such as persuasiveness or first-person reporting, covers 40 million linguistic patterns of English classified into over 100 categories of rhetorical effects (see http://www.cmu.edu/dietrich/english/research/docuscope.html for more information). Figure 4, taken from Ishizaki and Kaufer (2011), illustrates their process:
According to David Kaufer, the creator of DocuScope dictionaries, words or phrases which share an ‘aboutness’ can be grouped together in a hierarchical model of what he describes as Language Action Types (LATs); when someone runs his DocuScope dictionary on any given corpus, the software will search for exact matches based on the classifications he has made and report statistical frequencies for each category. While the DocuScope dictionaries are quite specific – in many ways it represents the creators’ view of how language functions – any corpus sent through their dictionary will be analysed in the same way. It doesn’t matter if you send all of Charles Dickens’ novels or emails from your mother or all of Shakespeare’s plays through the DocuScope classification schema; the dictionary will check for the exact same features every time. (The joy of DocuScope, and any string-matching software like this, is that every text uses these terms in a slightly different distributional pattern).
In other words, Ubiqu+Ity matches text to entries in the dictionaries, then computes the percentages of words per document that fall into LAT categories. Essentially, Ubiqu+Ity parses text and then tells you what rules the language falls under according to rules outlined in DocuScope dictionaries. With Ubiqu+Ity, we offer several versions of Kaufer’s dictionaries as well as the ability to create your own rules. What if, for example, you were interested in the language of gender? While the DocuScope dictionaries cover a huge range of rhetorical and linguistic features, it does not have a category explicitly devoted to gender, though terminology related to gender can appear in a variety of existing LATs.
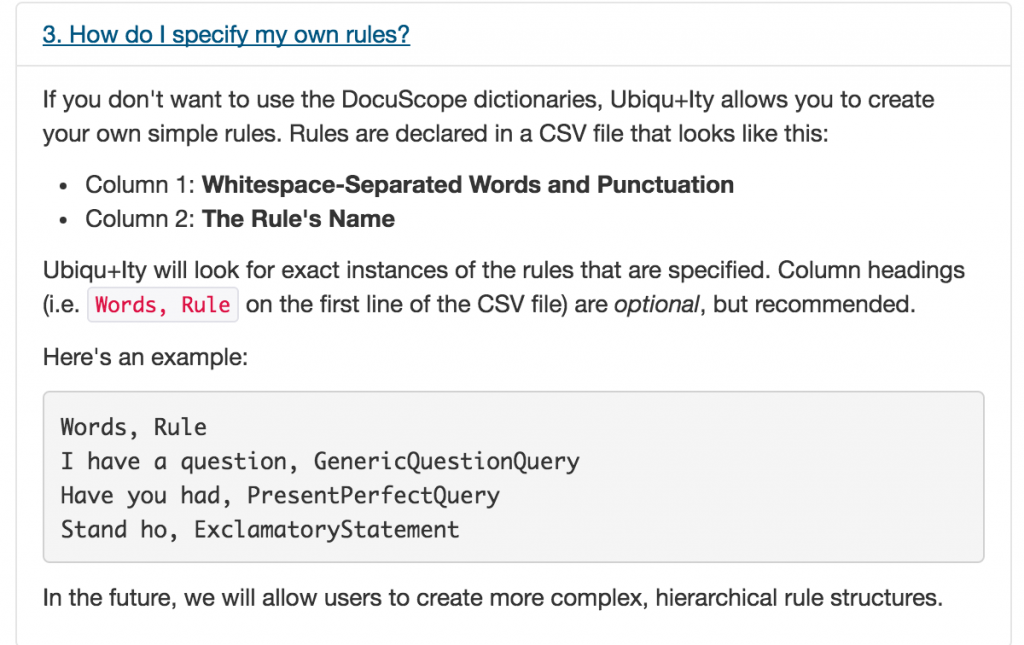
As these instructions suggest, we would need to create our new dictionary with a Comma-Separated Values (CSV) sheet in Excel. To the uninitiated, a Comma-Separated Values is a spreadsheet, but it is a specific kind of spreadsheet format. Where Excel files end with the suffix “.xlsx” (akin to “.docx”, the Word equivalent), CSV files end with the suffix “.csv”. It looks like any other spreadsheet in Excel, but this is a non-proprietary format, which means your data will move comfortably across any software program and retain its structure. The example provided for you above is a tiny bit deceptive though: when you save a file as a csv file, it will include the commas as column delineator for you, so the file will look like the example provided above. If you include any special characters (spaces, punctuation, etc.) in your rules, Ubiqu+Ity will search for that exact match. The table below shows two ways of formatting a set of rules:
| GOOD RULE FORMATTING | LESS GOOD RULE FORMATTING |
|---|---|
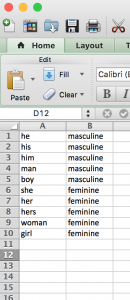 | 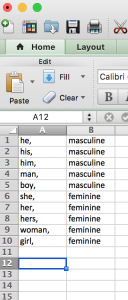 |
The one on the left is considered good rule formatting, because the computer will recognize it as
he, masculine
his, masculine
him, masculine
man, masculine
boy, masculine
she, feminine
her, feminine
hers, feminine
woman, feminine
girl, feminine
And the one on the right is considered less good, because to the computer this will read
he,, masculine
his,, masculine
him,, masculine
man,, masculine
boy,, masculine
she,, feminine
her,, feminine
hers,, feminine
woman,, feminine
girl,, feminine
(The one on the right may not necessarily be bad formatting outright, depending on what you’re interested in counting, but it definitely is less good formatting than the one on the left if you just want to count words and not words with punctuation!)
These lists can be as long or as short as you want, and they can be as specific or vague as you want: but whatever you tell Ubiqu+Ity to find, it will find. Once you upload your own dictionary, Ubiqu+Ity will use it to analyse your corpus, which is where the real fun starts. Here’s an example I ran using the VEP plain-text version of the Folger Digital Texts Shakespeare corpus.

click image to make bigger
This spreadsheet reports what percentage of each text uses each user-defined rule, just as it would with the DocuScope dictionaries. I’ve used the rules described above as a good example; the more categories you define, the larger your spreadsheet will be, of course. From here, you can do the usual Excel things, like graph them to see what the difference between ‘masculine’ and ‘feminine’ words are available in the plays:

Looking at this chart, I immediately want to know why Two Gentlemen of Verona has such a comparatively high volume of ‘feminine’ terms compared to other Shakespeare plays. But computers are also very good at identifying absence in ways that us humans cannot, so I am also interested in seeing why some plays like 1 Henry 6, Love’s Labours Lost, an a Midsummer Night’s Dream or have a smaller proportion of ‘masculine’ language overall – now I have specific research questions to tackle based on my initial findings.