
VEP's Metadata Builder
VEP’s Metadata Builder helps users navigate our corpora collections, which are vast in scale. The Metadata Builder provides metadata to users in an accessible, intelligible format, preventing users from having to decipher spreadsheets with more than 120 columns and 160,000 rows. This blog post will explain the motivations for creating the Metadata Builder and its main components, enabling users to understand how to use the tool.
Motivations
This tool was built to allows users to generate and download metadata spreadsheets of VEP corpora tailored to their own research interests. Users can merge metadata from multiple spreadsheets into one, filter their results, and engage with texts. The Metadata Builder provides options for downloading metadata and README documentation generated for tailor-made spreadsheets.
The Metadata Builder’s functionality is guided by data management best practices, which have vast implications for scholarly research. The builder ensures that users have access to the most up-to-date information.
Main Components
The Metadata Builder has five sequential steps:
- Pick the Documents
- Pick Metadata Fields
- Examine the Metadata
- Save the Metadata
- Save the README
1. PICK THE DOCUMENTS
The first step requires users to select the spreadsheet based on the VEP corpus they are interested in working with. The corpus spreadsheets contain information about corpus texts and files. Hovering over a corpus in the dropdown menu activates a tooltip displaying a brief corpus description. This description is replicated in the Step 1 box once a corpus is selected.
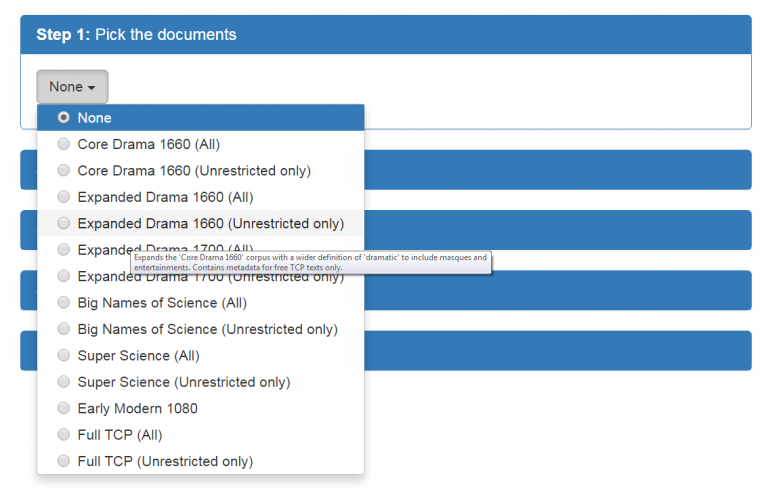
For each corpus, VEP offers two versions of metadata spreadsheets: ‘Unrestricted Only’ and ‘All’. To explain the difference, licensing agreements prevent VEP from releasing corpus text files made from restricted content in our source files. We can share, though, metadata about restricted files for research purposes. VEP provides users the option to download a spreadsheet of only the free files in a corpus (Unrestricted Only) or a spreadsheet of both free and restricted files (All). Unrestricted Only spreadsheets catalog the files available in our corpus downloads.
2. PICK THE METADATA FIELDS
This step of the Metadata Builder can be overwhelming for users not familiar with the data we provide to users. This step is the fun part, though, where users select specific information they are interested in.
To understand this step, users need to know that the Metadata Builder pulls information from multiple existing spreadsheets into one spreadsheet specified by the user. From these spreadsheets, users specify the exact columns they want to be dynamically generated as their dataset. Metadata spreadsheets are listed in bold print. Beside the metadata spreadsheet names are a question mark; hovering over it will display a brief description of the spreadsheet’s contents. Users can also view the spreadsheets by click on the source link to the right of the question mark, and the spreadsheet will appear in a new window. Dropdown menus to the right of the metadata spreadsheet list contains the names of all available columns from each linked spreadsheet, and hovering over the column names will display explanatory tooltips.
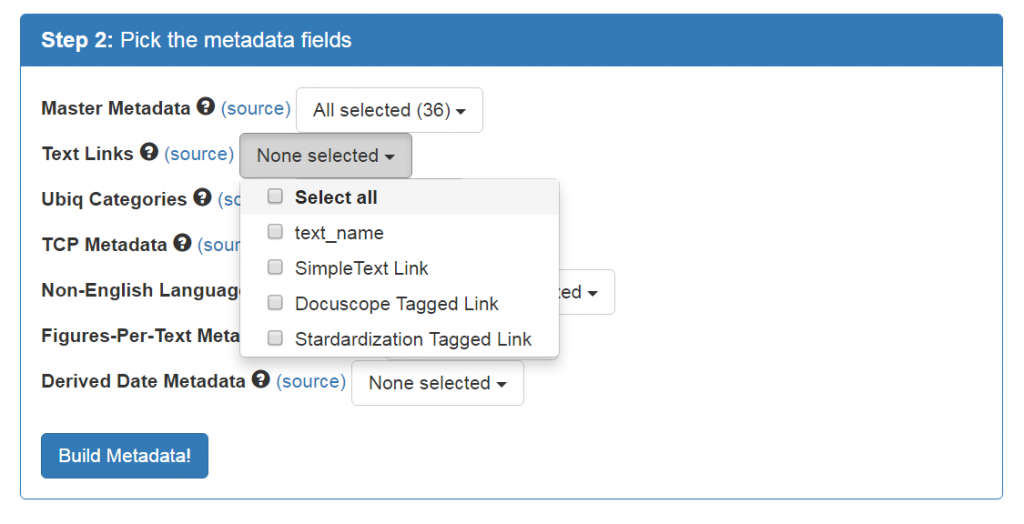
Below is a list that explains the metadata type spreadsheets you may see in step two:
- Master Metadata: This spreadsheet contains the corpus metadata provided by the curator, from text name and author to genre and number of pages in the text.
- Text Links: This spreadsheet contains links to files of unrestricted corpus content hosted on the VEP server. You can click on the links to read corpus texts.
- Ubiq Categories: This spreadsheet contains DocuScope LAT information for the files in the selected corpus.
- TCP Metadata: This spreadsheet contains metadata for all TCP digital texts, provided by the TCP.
Non-English Language Metadata: This spreadsheet lists primary and secondary languages for texts in the TCP that have the least amount of recognizable English in them. - Figures-Per-Text Metadata: This spreadsheet lists the number of FIGURE XML tags that appear in each TCP XML text. It is useful for finding texts that contain tables and images.
- Derived Date Metadata: This spreadsheet provides a programmatically selected date for all text in the TCP.
Users can select columns from as few as one metadata type spreadsheet to as many as columns from all the metadata type spreadsheets. Once users select metadata columns, a ‘Build Metadata’ button appears in the section. Pressing the button generates your data table in the section for step three.
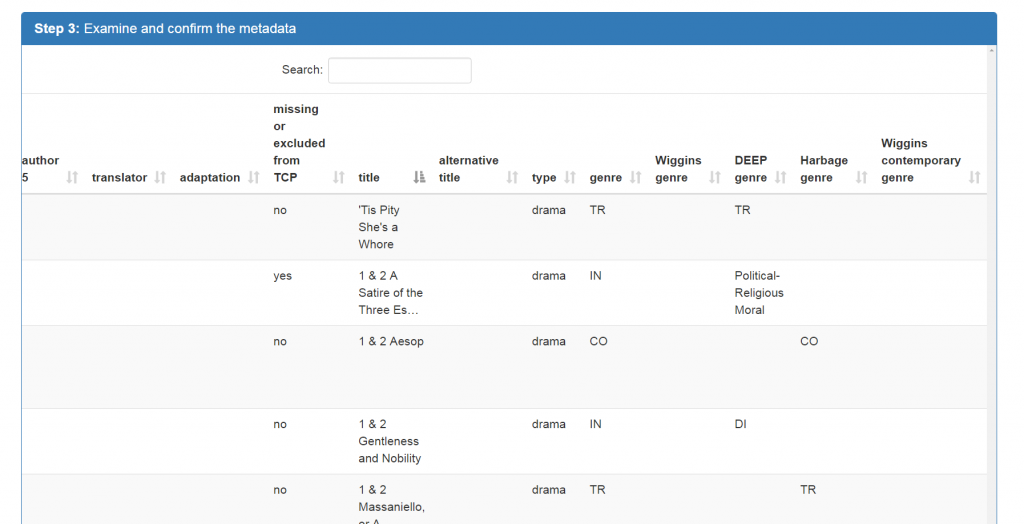
3. EXAMINE AND CONFIRM THE METADATA
This section renders a dataset based on the specifications entered in section two. It allows users to sort and search the metadata.
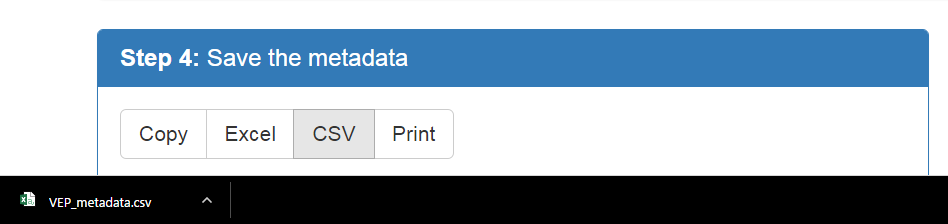
4. SAVE THE METADATA
This section allows users to save the generated datasets in a variety of formats. Users can save their datasets as Excel spreadsheets or CSVs. Users can optionally copy all of the information to their clipboard or print it.
5. SAVE THE README
This section contains a red button labeled ‘Download README.’ This step is important. Corpus Builder dynamically generates a README file that explains the contents of datasets.
Stay tuned for an upcoming blog post by Heather that walks users through what she finds to be the Metadata Builder’s most useful features!