
Editing Programmatically; or, Curating ‘Big Data’ Literature Corpora
No one has time to read and really understand all of the 1,476,894,257 words that comprise the Text Creation Partnership (TCP) digital texts. Considering that adults read on average 300 words a minute, it would take someone about 40 years to read every word in the TCP’s 61,000 texts. That 40-year estimate assumes 52 40-hour work weeks per year—no vacations, no holiday time, no sick time, no lunches or breaks.
How, then, does one editorially intervene in literature datasets at such scale? This task isn’t best carried out by more traditional methods of editing, where a human reader scrutinizes each text word by word and makes local changes. In this post, I will describe the research process I used to create VEP’s dictionary for standardizing the early modern spelling variation captured in TCP texts.
The goal of spelling standardization is to map variant spellings to a standard spelling, like “neuer” and “ne’er” to “never”. This standardization reduces noise in the dataset, providing analytical gains. It makes statistical analysis more accurate for users interested in counting and weighing textual features, like word frequency and part of speech parsing.
To ensure spelling consistency across the dataset, I researched the most frequent original spellings in the TCP texts. The team in Wisconsin decided to aim for a 95% standardization guarantee. To guarantee 95% standardization meant that, to do research efficiently, I had to research the most frequent words. As a result, I examined the behavior of 26,700 original spellings that occurred 2,000 or more times in the TCP. Their frequencies accounted for 95.04% of the total number of words in the TCP.
I searched for spellings in the TCP using command line. (Using UNIX is preferable to loading the 61,000 TCP texts into concordance software, as this is a heavy task for GUI-aided text processing.)
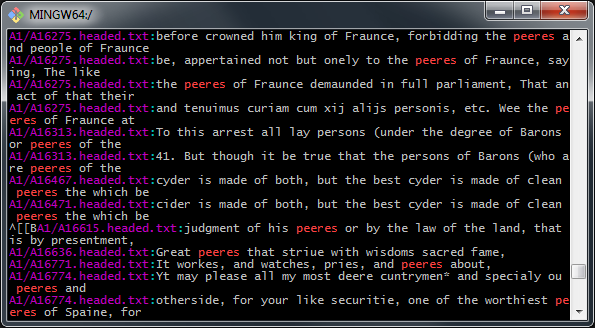 I examined thousands and thousands of instances of original spellings in brief context. It was an exercise in brevity, a trade-off between time and human labor. More often than not, the searches returned enough text surrounding the original spelling to understand meaning. (For example, look at the screenshot of my research above: it is obvious when the original spelling “peeres” means “peers” and when it means “pears”.) It would have been too time consuming to open TCP text files and read a paragraph of context for the original spellings. You wouldn’t be able to make a judgment call on a word in a day.
I examined thousands and thousands of instances of original spellings in brief context. It was an exercise in brevity, a trade-off between time and human labor. More often than not, the searches returned enough text surrounding the original spelling to understand meaning. (For example, look at the screenshot of my research above: it is obvious when the original spelling “peeres” means “peers” and when it means “pears”.) It would have been too time consuming to open TCP text files and read a paragraph of context for the original spellings. You wouldn’t be able to make a judgment call on a word in a day.I made the following decisions about original spellings:
- not to standardize original spellings because they were in what we already recognize as a standard form (e.g., “the”)
- not to standardize original spellings because they would have introduced too much error into the dataset
- to standardize original spellings to a certain spelling that was correct most of the time based on the behavior of the spelling across the entire TCP
Standardizing the most frequent original spellings resulted in major payoffs. To illustrate, compare the corpus frequency and rank in corpus for the word “Jews” in the two tables below.
1-Gram in the TCP (Original Spelling)
| n-gram | corpus frequency | rank in corpus |
|---|---|---|
| jews | 154027 | 849 |
1-Gram in the TCP (Standardized Spelling)
| n-gram | corpus frequency | rank in corpus |
|---|---|---|
| jews | 315702 | 458 |
Standardization located 161,678 more instances of the word “Jews” in the TCP, which has vast implications for those who study religion in early modern texts. Standardization yielded a 104% gain in recognition. For the curious, here are original spellings that are standardized to “Jews” in the VEP dictionary: ievves, ievvs, iewes, iews, jevves, jevvs, and jewes.
Data standardization is a form of editorial intervention that can have vast impacts for users. Granted, the provided standardization is a first step, and I invite others to expand upon my work. However, I argue that enforcing spelling consistency in the TCP corpora provides users with a cleaner, more accessible dataset. The standardized spelling makes the dataset easier to search. Users do not need to be experts in Early Modern English spelling conventions to extract meaningful information.
Curious to see what my editorial intervention looks like? I annotated Act 1 Scene 1 from Pericles. The annotations are provided in an interactive Text Viewer. (Image of the Text Viewer is directly below, and the link to access the Text Viewer is at the end of this entry.)
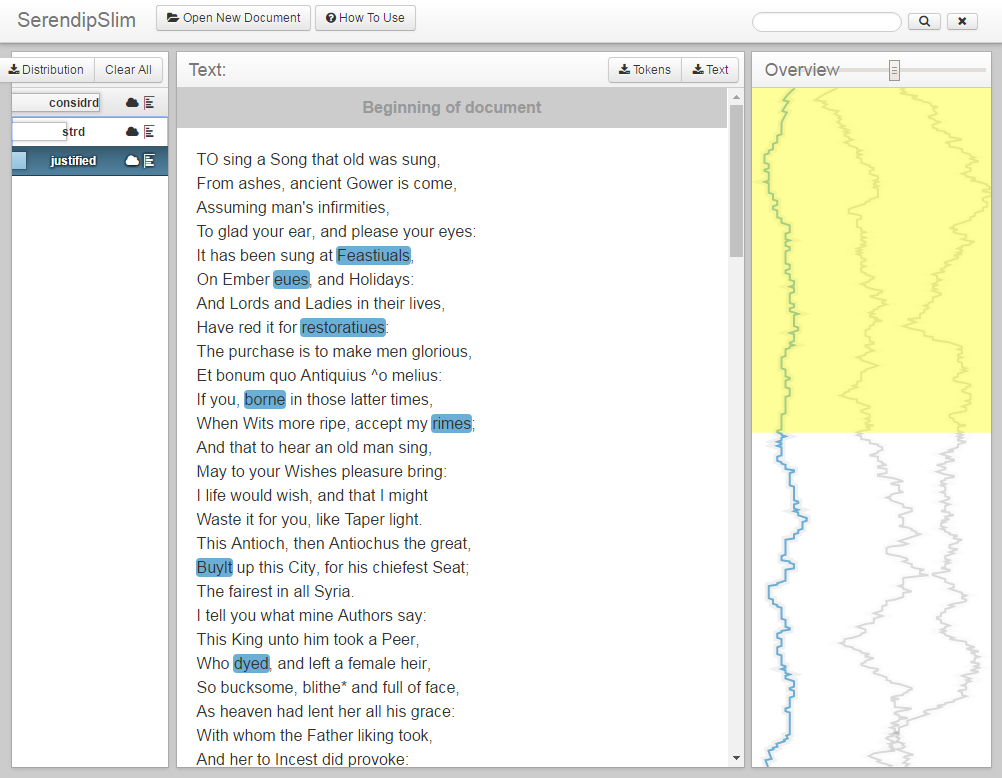
We are providing an annotated SimpleText example of Act 1 Scene 1 from Pericles. (A preview of the annotations are in the image above.) The text is annotated with three tags: Standardized, Researched, and Justified. Standardized highlights words that have had their spelling standardized. If a standardized spelling is incorrect in the Pericles scene, the annotation will explain why within the context of the TCP corpus. Researched highlights words that were researched in the process of compiling the standardization dictionary. These words were not provided standardized spellings because 1) they were in a recognized form and 2) the original spelling had too many different meanings to be standardized. Justified highlights words that were not standardized and provides a reason why (e.g., the word’s frequency was lower than 2,000).
View Annotations for Standardized Spelling in Pericles Act 1 Scene 1