
VEP SimpleText Format
Summary: This page allows users to familiarize themselves with the VEP SimpleText format and determine whether or not VEP text corpora meet their needs. This document introduces the VEP SimpleText format. It outlines the format’s rationale and goals, emphasizing the strengths and weaknesses of our text corpora. Moreover, it details how our texts can be used while linking to other sources for those interested in Early Modern English text corpora.
Outline
- Introduction to SimpleText
- SimpleText Rationale
- SimpleText Goals
- Formatting Decisions
- SimpleText Example
- SimpleText Uses
- Other Resources
Page Contents
Introduction to SimpleText
In the Visualizing English Print project, we have chosen to work with documents in a simplified format. This means that the corpora we produce, the tools we create and use, and the analyses we perform make use of this simplified format. The use of the SimpleText format has advantages and disadvantages. While we believe that it is the correct decision for our project at the current time, it might not be the right thing for others. This document explains the format and its rationale.
The idea of SimpleText is that we convert documents to a highly simplified format in order to make certain kinds of processing more standard and easier. That is, we intentionally remove much of the information that richer file formats contain, leaving files that can be processed in a simple fashion. Giving up the potential for the richer information that could be contained in a more complicated format, such as a structured markup language, has its costs. It means there are kinds of analyses we cannot perform with the data in the SimpleText format. However, this move enables us to perform the statistical analyses we are most interested in.
The SimpleText format is basically an ASCII text representation of the original document. While the details are available on the pipeline page, some key features are:
It is limited to the “ASCII Alphabet” – simplifying the range of characters expressed. It does not contain annotations and metadata (this information is kept separately). It does not attempt to preserve page layout or spacing, other than trying to keep the same line breaks as in the source files. It uses a simple version of spelling standardization. The main source of data for the VEP project is the TCP transcriptions of early modern texts. These texts are made available in a variety of structured markup forms (generally XML files with various schema). These files do not have the simplifications listed as “features” of the SimpleText format listed above. Indeed, we have had to build a processing pipeline to convert files, stripping the rich information contained in them.
Rationale for the SimpleText Format
Our goals in the VEP include demonstrating the utility of performing statistical analysis over large corpora of historical documents, which the SimpleText format is designed to support.
Some of the goals that we strive to achieve with our format are:
- We want to be able to use a wide range of standard tools. These tools may not work with more complicated formats.
- We want it to be easy to build and use software that works with the texts as data.
- We wanted a format that would be efficient to process for large quantities of texts.
- We wanted a lowest common denominator format that would allow us to use data from a variety of sources. While VEP focuses on providing access to TCP documents in simplified formats for statistical analysis, we would like our tools to be more broadly applicable. This aim means we need to be able to work with other corpora for testing (for example, we often test applications on collections of scientific abstracts).
- We want to reduce the variability introduced by the encoding process. While great care has been taken in the TCP project to produce as consistent a set as possible, the practical issues of an effort at such scale mean that encoding variation across the corpus is inevitable.
- More generally, we wanted to build tools that allow us to focus on the kinds of variability we are most interested in by minimizing the kinds of variability we aren’t. (See the discussion on kinds of variability.) For now, we are less interested in typography, spelling, and page layout. Key for us is variation between word-forms at the document and genre level. Consequently, we are prepared to forgo representations of internal document structure such as “chapter.”
- We want to separate meta-data from the text data itself, so the two can be processed independently (since different approaches are useful for each).
- We wanted to perform text processing as a pre-process, sharing processed texts to insure consistency between users.
- We are not concerned with providing good representations for large-scale human reading. Regardless, it is important that the data remains human readable (for example, to allow for close examination to confirm statistical findings). We are not concerned with being able to provide “book quality” editions from our data format.
- For some types of standardization (e.g., character usage, spelling) it is better to be consistent and well-documented and fast than to be a little bit more correct. These goals are specific to our project, and present tradeoffs. Others with different research needs might have different priorities.
To discuss our goals and success at achieving them, we will use a straw man comparison. The most obvious alternative to SimpleText would be to use the structured markup files available directly from the TCP project. For comparison, we consider a “hypothetical” validated markup edition (we will discuss why the actual available data is not this), encoding using XML files and a standardized schema. Although, it is important to note that such a format is necessarily complex: the wide range of documents means there is a vast amount of potential information to encode, and a schema capable of capturing it is necessarily complex.
USE OF STANDARD TOOLS, EASE OF PROGRAMMING, EFFICIENCY, CONSISTENCY (GOALS 1-3, 8):
Just about any program can read text files – ranging from Microsoft Word to the Mallet topic modeling system or Docuscope rhetorical analysis system from CMU. While some tools can be configured to read structured text, they must be configured specially. Similarly, while specific translators might be possible to convert from a structured text format to each individual required format, developing translation tools is beyond much of our target audience (especially since the structured format is likely to be complex). Because SimpleText “bakes in” the conversions, everyone using the data uses the same conversions. A single line of Python using the standard Python machine learning library (sklearn) can read in and word count the entire collection of early modern drama (1244 plays) in about 10 seconds (admittedly, on a modern fast PC). All 61,000+ files in the TCP can be read by the same line of code in approximately 900 seconds.
BROAD APPLICABILITY (GOAL 4):
SimpleText format provides a simple form that we can translate other corpora into (assuming they don’t come in this format to begin with). We have found it easy to build tools to create the simple format from our other data sources (e.g., scientific abstract collections, newspaper collections), although many corpora are distributed in simplified formats to begin with.
AVOIDING VARIABILITY FROM THE ENCODING PROCESS (GOAL 5):
The TCP was transcribed over a large number of years, by a large number of people. It tries to use complex encodings to fully capture the range of the documents. This leads to complexity at the “tag” label (for example, how different pieces of text are marked) as well as at the character level (the vocabulary of symbols used). Some of the differences are significant – but others are much more discretionary, and not necessarily consistent in how they are applied.
To illustrate, searching the TCP encoding to locate instances of generic forms is complicated due to the variety one encounters in DIV naming. A user interested in locating all play material in the TCP would miss a lot of dramatic material if they simply searched for DIV. A survey of DIV tags in Jonathan Hope’s Early Modern Drama corpora reveal dramatic material also tagged as type “drama”, “comedy”, “masque”, “pageant play”, “political drama”, “dumb show”, and “masque (operatic tableaux)”.
Encoding is inconsistent at the level of characters as well. While the TCP provides instructions on how to transcribe the symbols on the digitized microfilm images, transcribers are faced with representing dynamic early modern compositing practices. Apostrophes complicate transcription due their appearance on the digitized images, requiring transcribers to interpret how early modern compositors set type. Sometimes apostrophes in the digitized images look like upside down commas and left single quotations marks. To represent these instances, some transcribers used the grave accent (`), which is indicated by the TCP character entity list to be used for spacing since it does not combine with preceding characters. Some transcribers even used two grave accents to indicate opening quotations for cited material based on the type used in the digitized images.
FOCUSING ON VARIABILITY OF INTEREST (GOAL 6):
In the VEP project, our focus is on certain kinds of variability. For example, we want tosee trends in what people write about and the styles that they use in writing about it, over the more low-level details such as how their words were spelled or set on the page. To the extent that we can, we standardize the early modern spellings contained in TCP documents to perform meaningful statistical analysis. Our methods treat the word tokens “fashiond” and “fashion’d” the same as “fashioned”, variations in Early Modern English spelling that might interest users of TCP texts. We standardize word tokens to assist the algorithms that process SimpleText because they base calculations on exact tokens. An algorithm treats “fashiond” and “fashion’d” as two different tokens based on their characters, while a user may recognize that both are past participles.
SEPARATING DATA AND META-DATA (GOAL 7):
Traditional data management tools (databases, spreadsheets) are good at handling meta-data. For analysis, we wish to focus on the words written in the time period.
IT IS MORE IMPORTANT TO BE CONSISTENT AND DOCUMENTABLE THAN CORRECT (GOAL 10):
Because the steps of processing documents are just steps in a broader interpretive chain, and because we are interested at scale, being consistent and easy to understand is more important than maximizing accuracy of standardization.
For example, we prefer to list a set of easily documentable but simple replacement rules than to use a more complex process that might better infer correct decisions. Inferring correct decisions best positions VEP to conduct meaningful analyses. Certain Early Modern English spelling variations complicate interpretation, like “bee.” The spelling “bee”, quite frequent in the TCP documents, can mean the insect or the verb. Searching through Jonathan Hope’s Early Modern Drama corpus ordered by TCP ID, in the first 1,000 hits of the spelling “bee” only 17 instances referred to the honey-making insect. Based on the frequency of 1.7%, it was relatively safe to assume that so as not to skew results “bee” should be standardized to the verb form “be.” Read more here.
Specific Decisions in the Format
Character Cleaning: We convert non-ASCII characters to ASCII “near-matches” using a mapping table that does not consider context (i.e., a specific Unicode character always maps to the same ASCII character).
This was necessary because many tools we wanted to use do not handle Unicode characters correctly. Some tools that do handle Unicode characters do not handle them consistently, or are inconsistent between versions.
The loss of richness in character set has the advantage that this richness usually encodes subtle variation that we are less concerned with. For example, while the wide variety of dashes one sees encoded in the TCP are probably different in interesting ways, it is probably not meaningful in the kinds of analysis that we are interested in. Even if it were, it is not clear that these different dash types were consistently applied by the transcribers (some distinctions are based on semantics not appearance, and some are only subtly different in appearance).
Similarly, by removing diacritic marks (such as umlauts) and typeface distinctions (such as italics), we lose information about how people spell, and possibly intended pronunciation. However, losing such marks rarely changes the meaning or recognizability of the words – and any such loss is probably offset by the fact that mishandling of the marks (if they existed) is likely to lead to errors, except more unpredictably.
No MetaData – only Textual Data: We encode only words that are intended to be included as part of analysis, that is those words that we expect that the reader of the page would consider part of the text. While this makes it impossible to include much information beyond the words themselves (such as layout or other cues to the reader differentiating types of text on the page).
This simplification is probably the most problematic of all, because it is difficult to apply consistently, and removing this information makes it impossible to make other distinctions later. It also leads to potentially different versions of the format, depending on how this choice is made.
For example, consider the important special case of drama (i.e., things meant for performance). The TCP files include markings to distinguish stage direction, speaker designation, etc. For some analysis, a scholar might be interested only in the words actually spoken by the characters. We therefore have a variant of the SimpleText format that includes (to the extent possible) only such words, omitting stage directions etc. However, this SimpleText variant cannot be produced from a more inclusive SimpleText variant.
Our default (other than the drama variant of SimpleText) is to be relatively inclusive, including most kinds of text that appear on the page. However, this is a case of simplicity and documentability over correctness: we have documented what specific TCP tags are (and are not) included, and use a simple exclusion criterion.
This simplification is costly in many ways. As an example, text indicated as headings and titles in TCP markup are not distinguished from the main body of the text once extracted in SimpleText form. However, because these are typically small in quantity, we would hope they would not skew statistical analysis (although, “Chapter” often shows up as a more common word than one would expect).
No Formatting: While it would be possible to use spacing and other text layout tricks to encode more layout information, we have chosen not to. In general, the spacing in SimpleText files is not meaningful. This includes line breaks. While the processing tools attempt to preserve line breaks, and to insert them at paragraph or other spacing breaks in the source material, this is not guaranteed.
Example
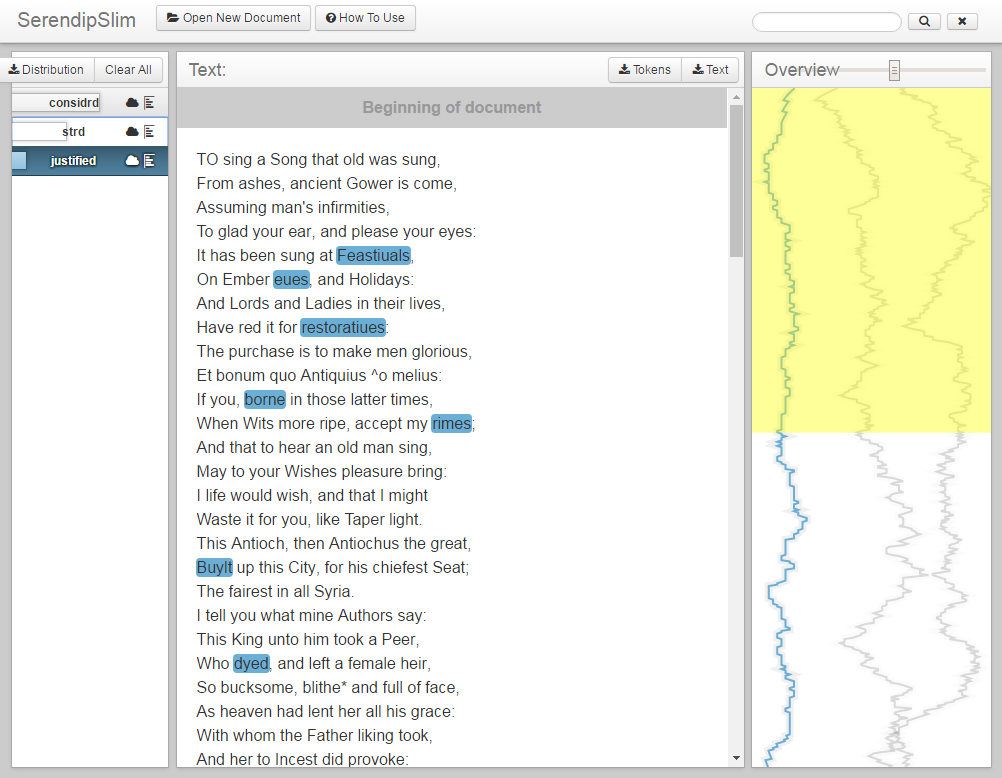
We are providing an annotated SimpleText example of Act 1 Scene 1 from Pericles. (A preview of the annotations are in the image above.) The text is annotated with three tags: Standardized, Researched, and Justified. Standardized highlights words that have had their spelling standardized. If a standardized spelling is incorrect in the Pericles scene, the annotation will explain why within the context of the TCP corpus. Researched highlights words that were researched in the process of compiling the standardization dictionary. These words were not provided standardized spellings because 1) they were in a recognized form and 2) the original spelling had too many different meanings to be standardized. Justified highlights words that were not standardized and provides a reason why (e.g., the word’s frequency was lower than 2,000).
View Pericles Act 1 Scene 1 SimpleText with Annotations
VEP SimpleText Uses
The SimpleText format ensures that texts are pre-processed and ready to use out of the box. Our texts are designed to maximize machine readability in a plain-text format: no metadata, no XML, standardized spelling, and standardized typographical conventions.
Below are examples of what you can do with VEP SimpleText corpora.
Curate specific subcorpora related to your field of study and/or scholarly interests (such as all texts by the Royal Society, for example).
(Broken image link) Generate visualizations to explore sub-corpora, such as the works of an author. One visualization technique is the word cloud, which displays words according to their prominence within a corpus. (Try Wordle).

Explore editorial choices required for creating machine-readable digital versions of printed materials. You can compare and contrast standardized spelling versions of TCP texts to versions without standardized spelling. You can also run our original spelling versions of TCP corpora through spelling standardization software, like VARD.
Make a Twitter bot to tweet the complete works of your favorite historical texts (e.g. Gondibot, tweeting Davenant’s Gondibert).
Challenge dates of ‘first recorded usage’ in the Oxford English Dictionary.
Annotate texts for part of speech or lemma to model the structure of historical language using resources such as MorphAdorner, Polyglot, Natural Language Toolkit, and the Stanford Part of Speech tagset.
Identify proper nouns in the TCP texts using Named Entity Recognition with the Stanford NER kit for further analyses (e.g., network analysis).
Use concordance software to identify specific words in a context window, explore statistical relationships between words, and observe word frequencies. See this AntConc tutorial on the Programming Historian by our collaborator Heather Froehlich for a getting-started tutorial on this popular concordance software, or play around with the EEBO-TCP dataset in CQPweb.
Use multivariate text-tagging programs and/or word vector models to explore many dimensions of language in lots of text documents at once. VEP’s Ubiqu+Ity tags texts for the rhetorical dimensions of language. If you use Ubiqu+Ity, consider using the dictionary created by Michael Witmore for analyzing language in Shakespearean drama.
Trace the use of specific words or concepts across a corpus or subcorpus using VEP’s TextDNA, which borrows genomic sequence alignment techniques for literary visualization.
Make topic models. VEP’s Serendip visualizes topic model output, allowing users to explore how documents relate to each other and drill down into texts.
Other Resources
Shakespeare His Contemporaries provides linguistically annotated, human-readable texts for download in multiple formats.
Early Print has excellent resources for EEBO-TCP Phase I texts: an n-gram reader, a concordancer. However, it is not an interface to the texts.
Historical Dictionaries Historical Thesaurus of the Oxford English Dictionary Lexicons of Early Modern English (LEME) Middle English Dictionary Online.
Explore the Original Files
EEBO-TCP documentation
EEBO-TCP Tagging Cheatsheet: alphabetical list of tags with brief descriptions
Text Creation Partnership Character Entity List
Univeristy of Michigan TCP repository
University of Michigan EEBO-TCP Full Text Search
University of Oxford Text Archive TCP Full Text Search
Mirror of ECCO-TCP (18thC, via eMOP)