Boxer: Interactive Comparison of Classification Results #
The Boxer project was an effort to develop visualization and interactive strategies for examining the results of machine learning classifiers. Our focus is on comparison: we seek to develop methods to enable machine learning practitioners to compare results between different scenarios, either to make comparisons between different classifiers, or to make comparisons within a given testing set to identify groups of items. Boxer treats classifiers as black boxes: it examines the input/output pairs of testing data (e.g., test sets and their responses).
Our ideas are embodied into a system called Boxer. There were two “versions” - initially Boxer was designed for discrete choice classifiers. An updated version of Boxer supports continuously valued binary classifiers. The new system (that we sometimes refer to as Continuous Boxer or CBoxer) is not actually a new system: it is just a new set of features in the one Boxer system. Boxer automatically enables appropriate features for the data sets.
If you want to try to use Boxer, there is a bit of a user guide that includes a walkthrough of the use cases described in the papers. The system is open. However, if you just want to use the system, it is available online. The online system can load any of the example datasets from the paper (and includes view configurations to match the examples), but it also allows you to load your own data.
If you want to learn about Boxer, we recommend reading the papers and/or watching the videos to get the basic ideas. Then work through a use case or two using the sample data we provide in the online system.
This site has a brief introduction, videos, an online demo, and the beginnings of a user guide.
Boxer #
Boxer is a system for comparing the results of machine learning classifiers. Please see the EuroVis 2020 paper for a description. The Boxer system is available open source. The source repository is on GitHub. However, if you want to use the system, it is available online.
Motivation #
Machine learning practitioners often perform experiments that compare classification results. Users gather the results of different classifiers and/or data perturbations on a collection of testing examples. Results data are stored and analyzed for tasks such as model selection, hyper-parameter tuning, data quality assessment, fairness testing, and gaining insight about the underlying data. Classifier comparison experiments are typically evaluated by summary statistics of model performance, such as accuracy, F1, and related metrics. These aggregate measures provide for a quick summary, but not detailed examination. Examining performance on different subsets of data can provide insights into the models (e.g., to understand performance for future improvement), the data (e.g., to understand data quality issues to improve cleaning), or the underlying phenomena (e.g., to identify potential causal relationships). Making decisions solely on aggregated data can lead to missing important aspects of classifier performance. To perform such closer examination, practitioners rely on scripting and existing tools in their standard workflows. The lack of specific tooling makes the process laborious and comparisons challenging, limiting how often experiments are examined in detail.
Main Contribution #
Boxer is a comprehensive approach for interactive comparison of machine learning classifier results. It has been implemented in a prototype system. We show how Boxer enables users to perform a variety of tasks in assessing machine learning systems.
Innovations #
The approach to classifier comparison that combines subset identification, metric selection, and comparative visualization to enable detailed comparison in classifier results.
The architecture of multiple selections and set algebra that allows users to flexibly link views and specify data subsets of interest.
Interactive techniques and visual designs that make the approach practical. These key ideas should be applicable in other systems for interactive comparison within complex data.
Example of Boxer System #
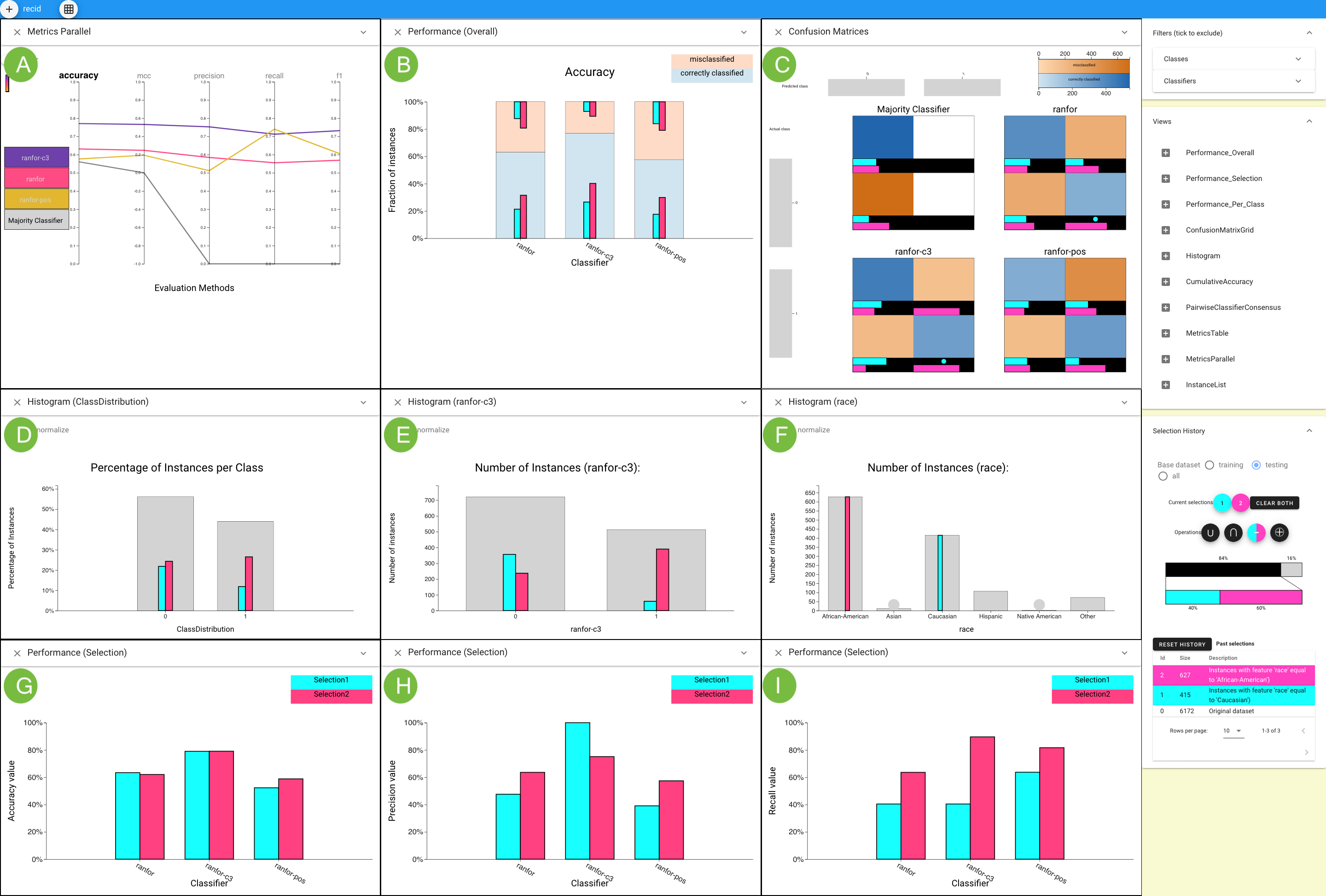 This figure shows how Boxer’s flexible mechanisms can be used to analyze whether a person will commit a crime within two years based on the data set contains 6,172 instances. Parallel Metrics view (A) shows the C3 classifier has better performance by all metrics. A histogram of race (F) selects Caucasian (cyan) and African-American (pink) instances. The Overall Performance view (B) shows C3’s overall higher precision, but a lack of overlap with cyan. The Confusion Matrix (C) Grid view shows many false positives for African-Americans and many false negatives for Caucasians for C3. Histograms show the distribution of selected sets across the actual (D) and the C3-predicted class (E). The Performance Selection views in the third line compare accuracy (G) , precision (H) , and recall (I) for C3 on the subsets.
This figure shows how Boxer’s flexible mechanisms can be used to analyze whether a person will commit a crime within two years based on the data set contains 6,172 instances. Parallel Metrics view (A) shows the C3 classifier has better performance by all metrics. A histogram of race (F) selects Caucasian (cyan) and African-American (pink) instances. The Overall Performance view (B) shows C3’s overall higher precision, but a lack of overlap with cyan. The Confusion Matrix (C) Grid view shows many false positives for African-Americans and many false negatives for Caucasians for C3. Histograms show the distribution of selected sets across the actual (D) and the C3-predicted class (E). The Performance Selection views in the third line compare accuracy (G) , precision (H) , and recall (I) for C3 on the subsets.
To cite boxer: #
Michael Gleicher, Aditya Barve, Xinyu Yu, and Florian Heimerl. Boxer: Interactive Comparison of Classifier Results. Computer Graphics Forum 39 (3), June 2020.
CBoxer #
The Continuous Boxer system (CBoxer) extends Boxer to assess continuously-valued binary classifiers that is sufficiently flexible to adapt to a wide range of tasks. It focuses on comparison as a strategy, enabling the approach to support the wide range of tasks encountered by practitioners. Tasks are framed as comparison, either between models or among subsets of items, providing a common basis. CBoxer is not a separate system: when a dataset is loaded, Boxer automatically enables appropriate features.
Motivation #
Classifier assessment is more challenging when the result is continuously valued, rather than a discrete choice. Classification models often output a continuous valued score for their predictions. Sometimes, these scores are used directly to quantify the quality of the prediction. Even if the scores are ultimately thresholded to provide a binary decision, analysis of the scores can provide useful insights on classifier performance. Therefore, assessment must consider both correctness and score. Current methods address specific tasks. While these tools enhance the baseline of scripting within standard workflows, they do not extend to the diverse range of tasks users encounter, either by adapting to new situations or combining effectively to provide richer analyses.
Main Contribution #
CBoxer provides a more comprehensive approach using a combination of task-specific solutions and standard views and coordination mechanisms. It support the assessment of continuouslyvalued binary classifiers that is sufficiently flexible to adapt to a wide range of tasks.
Innovations #
- A set of views that support classifier assessment and allow flexible combination to perform detailed analyses.
- A set of design elements, such as trinary classification, that enable visualizations that readily adapt to interactive comparison.
- The mechanisms to discourage over-generalization.
- An example of how thinking in terms of comparison can enable the design of flexible tools that serve a variety of tasks, many of which may not obviously be comparison.
Example of CBoxer #
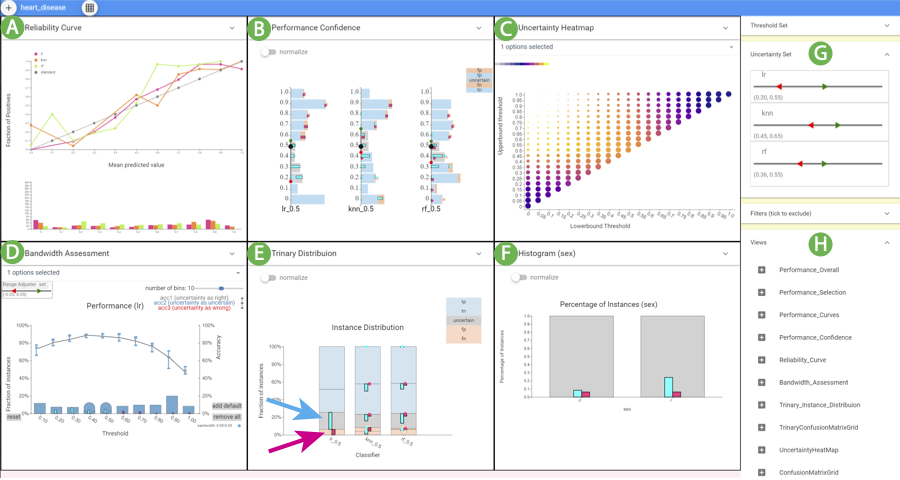 The CBoxer system assessing three classifiers for the disease prediction problem. (A) Reliability Curve view, (B) Performance Confidence view, (C) Uncertainty Heatmap view, (D) Bandwidth
Assessment view, (E) Trinary Distribution view, and (F) Histogram view. The Probability Control panel (G) and Views Control panel (H)
were used to configure the display. The user has selected the false positive (magenta) and uncertain (cyan) items for the LR classifier in
(E) as indicated by the arrows. These selections can be seen in other views, including (F) that shows that the classifier is more likely to be
uncertain for men.
The CBoxer system assessing three classifiers for the disease prediction problem. (A) Reliability Curve view, (B) Performance Confidence view, (C) Uncertainty Heatmap view, (D) Bandwidth
Assessment view, (E) Trinary Distribution view, and (F) Histogram view. The Probability Control panel (G) and Views Control panel (H)
were used to configure the display. The user has selected the false positive (magenta) and uncertain (cyan) items for the LR classifier in
(E) as indicated by the arrows. These selections can be seen in other views, including (F) that shows that the classifier is more likely to be
uncertain for men.
We are also in the process of extending Boxer to handle other types of machine learning problems and we are trying to make the system easier to use through documentation and a guidance system.
Acknowledgements #
The Boxer project is led by Prof. Michael Gleicher. The original system was implemented by Aditya Barve and Xinyi Yu. Florian Heimerl and Yuheng Chen helped with the design work. A number of our colleagues have provided data and feedback.
This work was in part supported by NSF award 1830242 and DARPA award FA8750-17-2-0107.